Automatic SIMD vectorization support in PyPy
Hi everyone,
it took some time to catch up with the JIT refacrtorings merged in this summer. But, (drums) we are happy to announce that:
Good news is that it is not specifically targeted for the NumPy library and the PyPy virtual machine. Any interpreter (written in RPython) is able make use of the vectorization. For more information about that take a look here, or consult the documentation. For the time being it is not turn on by default, so be sure to enable it by specifying --jit vec=1 before running your program.
If your language (written in RPython) contains many array/matrix operations, you can easily integrate the optimization by adding the parameter 'vec=1' to the JitDriver.
The following tests tests show the speedup of the core functions commonly used in Python code interfacing with NumPy, on CPython with NumPy, on the PyPy 2.6.1 relased several weeks ago, and on PyPy 15.11 to be released soon. Timeit was used to test the time needed to run the operation in the plot title on various vector (lower case) and square matrix (upper case) sizes displayed on the X axis. The Y axis shows the speedup compared to CPython 2.7.10. This means that higher is better.
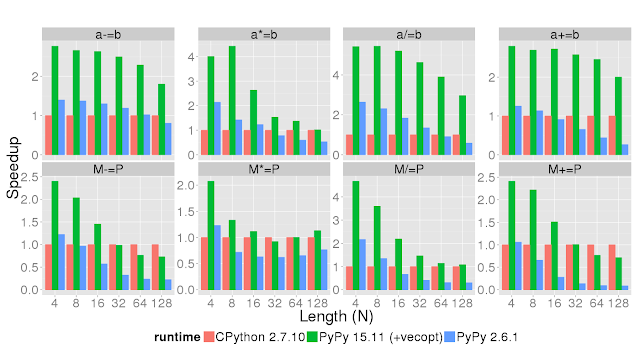
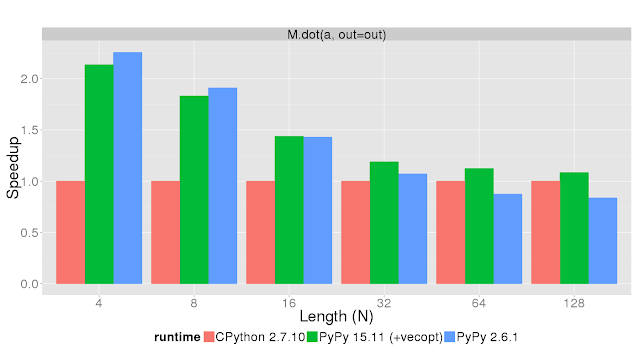
In comparison to PyPy 2.6.1, the speedup greatly improved. The hardware support really strips down the runtime of the vector and matrix operations. There is another operation we would like to highlight: the dot product.
It is a very common operation in numerics and PyPy now (given a moderate sized matrix and vector) decreases the time spent in that operation. See for yourself:
 These are nice improvements in the NumPyPy library and we got to a competitive level only making use of SSE4.1.
These are nice improvements in the NumPyPy library and we got to a competitive level only making use of SSE4.1.
This is not the end of the road. The GSoC project showed that it is possible to implement this optimization in PyPy. There might be other improvements we can make to carry this further:
The PyPy Team
it took some time to catch up with the JIT refacrtorings merged in this summer. But, (drums) we are happy to announce that:
The next release of PyPy, "PyPy 4.0.0", will ship the new auto vectorizer
The goal of this project was to increase the speed of numerical applications in both the NumPyPy library and for arbitrary Python programs. In PyPy we have focused a lot on improvements in the 'typical python workload', which usually involves object and string manipulations, mostly for web development. We're hoping with this work that we'll continue improving the other very important Python use case - numerics.What it can do!
It targets numerics only. It will not execute object manipulations faster, but it is capable of enhancing common vector and matrix operations.Good news is that it is not specifically targeted for the NumPy library and the PyPy virtual machine. Any interpreter (written in RPython) is able make use of the vectorization. For more information about that take a look here, or consult the documentation. For the time being it is not turn on by default, so be sure to enable it by specifying --jit vec=1 before running your program.
If your language (written in RPython) contains many array/matrix operations, you can easily integrate the optimization by adding the parameter 'vec=1' to the JitDriver.
NumPyPy Improvements
Let's take a look at the core functions of the NumPyPy library (*).The following tests tests show the speedup of the core functions commonly used in Python code interfacing with NumPy, on CPython with NumPy, on the PyPy 2.6.1 relased several weeks ago, and on PyPy 15.11 to be released soon. Timeit was used to test the time needed to run the operation in the plot title on various vector (lower case) and square matrix (upper case) sizes displayed on the X axis. The Y axis shows the speedup compared to CPython 2.7.10. This means that higher is better.

It is a very common operation in numerics and PyPy now (given a moderate sized matrix and vector) decreases the time spent in that operation. See for yourself:
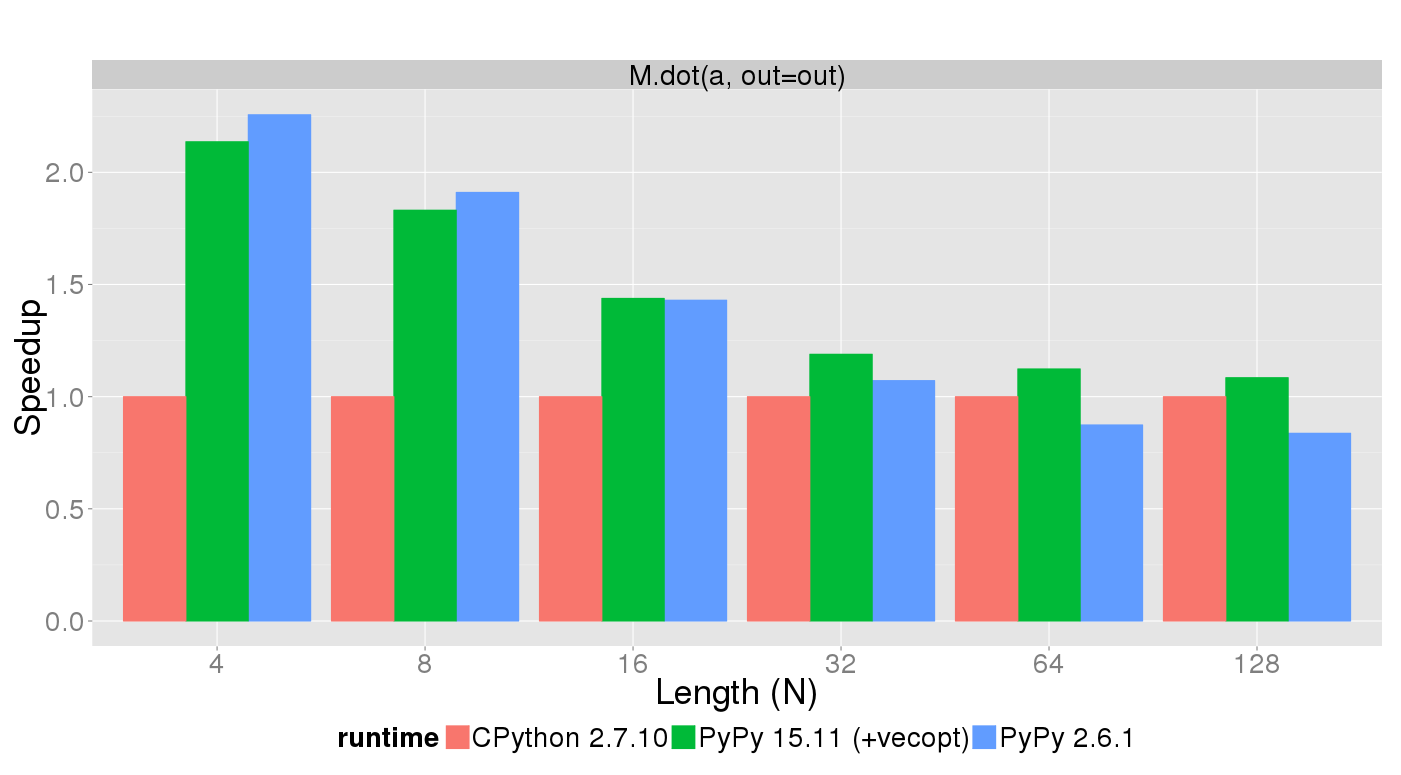
Future work
This is not the end of the road. The GSoC project showed that it is possible to implement this optimization in PyPy. There might be other improvements we can make to carry this further:
- Check alignment at runtime to increase the memory throughput of the CPU
- Support the AVX vector extension which (at least) doubles the size of the vector register
- Handle each and every corner case in Python traces to enable it globally
- Do not rely only on loading operations to trigger the analysis, there might be cases where combination of floating point values could be done in parallel
The PyPy Team
Comments
Which BLAS are u using for CPython Numpy? OpenBlas?
How does it compare to numexpr on those benchmarks?
Also, any plan of addressing one of the killer features of numexpr, that is the fact that an operation like y += a1*x1 + a2*x2 + a3*x3 will create 5 temporary vectors and make a horrible usage of the CPU cache?
I don't know anyone who uses NumPy for arrays with less than 128 elements.
Your own benchmark shows NumPypy is much slower than NumPy for large arrays...
NumPyPy is currently not complete. Trying to evaluate any numexpr gives a strange error. I guess the problem is a missing field not exported by NumPyPy.
However we will see how far we can get with this approach. I have made some thoughts on how we could make good use of graphics cards, but this is future work.
Nice work!