PyPy v7.3.7: bugfix release of python 3.7 and 3.8
PyPy v7.3.7: bug-fix release of 3.7, 3.8
We are releasing a PyPy 7.3.7 to fix the recent 7.3.6 release's binary
incompatibility with the previous 7.3.x releases. We mistakenly added fields
to PyFrameObject and PyDateTime_CAPI that broke the promise of binary
compatibility, which means that c-extension wheels compiled for 7.3.5 will not
work with 7.3.6 and via-versa. Please do not use 7.3.6.
We have added a cursory test for binary API breakage to the https://github.com/pypy/binary-testing repo which hopefully will prevent such mistakes in the future.
Additionally, a few smaller bugs were fixed:
Use
uintfor therequestargument offcntl.ioctl(issue 3568)Fix incorrect tracing of while True` body in 3.8 (issue 3577)
Properly close resources when using a
conncurrent.futures.ProcessPool(issue 3317)Fix the value of
LIBDIRin_sysconfigdatain 3.8 (issue 3582)
You can find links to download the v7.3.7 releases here:
We would like to thank our donors for the continued support of the PyPy project. If PyPy is not quite good enough for your needs, we are available for direct consulting work. If PyPy is helping you out, we would love to hear about it and encourage submissions to our blog site via a pull request to https://github.com/pypy/pypy.org
We would also like to thank our contributors and encourage new people to join the project. PyPy has many layers and we need help with all of them: PyPy and RPython documentation improvements, tweaking popular modules to run on PyPy, or general help with making RPython's JIT even better.
If you are a python library maintainer and use C-extensions, please consider making a CFFI / cppyy version of your library that would be performant on PyPy. In any case both cibuildwheel and the multibuild system support building wheels for PyPy.
What is PyPy?
PyPy is a Python interpreter, a drop-in replacement for CPython 2.7, 3.7, and 3.8. It's fast (PyPy and CPython 3.7.4 performance comparison) due to its integrated tracing JIT compiler.
We also welcome developers of other dynamic languages to see what RPython can do for them.
This PyPy release supports:
x86 machines on most common operating systems (Linux 32/64 bits, Mac OS X 64 bits, Windows 64 bits, OpenBSD, FreeBSD)
64-bit ARM machines running Linux.
s390x running Linux
PyPy does support ARM 32 bit and PPC64 processors, but does not release binaries.
PyPy v7.3.6: release of python 2.7, 3.7, and 3.8
PyPy v7.3.6: release of python 2.7, 3.7, and 3.8-beta
The PyPy team is proud to release version 7.3.6 of PyPy, which includes three different interpreters:
PyPy2.7, which is an interpreter supporting the syntax and the features of Python 2.7 including the stdlib for CPython 2.7.18+ (the
+is for backported security updates)PyPy3.7, which is an interpreter supporting the syntax and the features of Python 3.7, including the stdlib for CPython 3.7.12.
PyPy3.8, which is an interpreter supporting the syntax and the features of Python 3.8, including the stdlib for CPython 3.8.12. Since this is our first release of the interpreter, we relate to this as "beta" quality. We welcome testing of this version, if you discover incompatibilites, please report them so we can gain confidence in the version.
The interpreters are based on much the same codebase, thus the multiple release. This is a micro release, all APIs are compatible with the other 7.3 releases. Highlights of the release, since the release of 7.3.5 in May 2021, include:
We have merged a backend for HPy, the better C-API interface. The backend implements HPy version 0.0.3.
Translation of PyPy into a binary, known to be slow, is now about 40% faster. On a modern machine, PyPy3.8 can translate in about 20 minutes.
PyPy Windows 64 is now available on conda-forge, along with nearly 700 commonly used binary packages. This new offering joins the more than 1000 conda packages for PyPy on Linux and macOS. Many thanks to the conda-forge maintainers for pushing this forward over the past 18 months.
Speed improvements were made to
io,sum,_ssland more. These were done in response to user feedback.The 3.8 version of the release contains a beta-quality improvement to the JIT to better support compiling huge Python functions by breaking them up into smaller pieces.
The release of Python3.8 required a concerted effort. We were greatly helped by @isidentical (Batuhan Taskaya) and other new contributors.
The 3.8 package now uses the same layout as CPython, and many of the PyPy-specific changes to
sysconfig,distutils.sysconfig, anddistutils.commands.install.pyhave been removed. Thestdlibnow is located in<base>/lib/pypy3.8onposixsystems, and in<base>/Libon Windows. The include files on windows remain the same. Onposixthey are in<base>/include/pypy3.8. Note we still use thepypyprefix to prevent mixing the files with CPython (which usespython.
We recommend updating. You can find links to download the v7.3.6 releases here:
We would like to thank our donors for the continued support of the PyPy project. If PyPy is not quite good enough for your needs, we are available for direct consulting work. If PyPy is helping you out, we would love to hear about it and encourage submissions to our blog via a pull request to https://github.com/pypy/pypy.org
We would also like to thank our contributors and encourage new people to join the project. PyPy has many layers and we need help with all of them: PyPy and RPython documentation improvements, tweaking popular modules to run on PyPy, or general help with making RPython's JIT even better. Since the previous release, we have accepted contributions from 7 new contributors, thanks for pitching in, and welcome to the project!
If you are a python library maintainer and use C-extensions, please consider making a CFFI / cppyy version of your library that would be performant on PyPy. In any case both cibuildwheel and the multibuild system support building wheels for PyPy.
What is PyPy?
PyPy is a Python interpreter, a drop-in replacement for CPython 2.7, 3.7, and soon 3.8. It's fast (PyPy and CPython 3.7.4 performance comparison) due to its integrated tracing JIT compiler.
We also welcome developers of other dynamic languages to see what RPython can do for them.
This PyPy release supports:
x86 machines on most common operating systems (Linux 32/64 bits, Mac OS X 64 bits, Windows 64 bits, OpenBSD, FreeBSD)
big- and little-endian variants of PPC64 running Linux,
s390x running Linux
64-bit ARM machines running Linux.
PyPy does support Windows 32-bit and ARM 32 bit processors, but does not release binaries. Please reach out to us if you wish to sponsor releases for those platforms.
What else is new?
For more information about the 7.3.6 release, see the full changelog.
Please update, and continue to help us make PyPy better.
Cheers, The PyPy team
Better JIT Support for Auto-Generated Python Code
Performance Cliffs
A common bad property of many different JIT compilers is that of a "performance cliff": A seemingly reasonable code change, leading to massively reduced performance due to hitting some weird property of the JIT compiler that's not easy to understand for the programmer (e.g. here's a blog post about the fix of a performance cliff when running React on V8). Hitting a performance cliff as a programmer can be intensely frustrating and turn people off from using PyPy altogether. Recently we've been working on trying to remove some of PyPy's performance cliffs, and this post describes one such effort.
The problem showed up in an issue where somebody found the performance of their website using Tornado a lot worse than what various benchmarks suggested. It took some careful digging to figure out what caused the problem: The slow performance was caused by the huge functions that the Tornado templating engine creates. These functions lead the JIT to behave in unproductive ways. In this blog post I'll describe why the problem occurs and how we fixed it.
Problem
After quite a bit of debugging we narrowed down the problem to the following reproducer: If you render a big HTML template (example) using the Tornado templating engine, the template rendering is really not any faster than CPython. A small template doesn't show this behavior, and other parts of Tornado seem to perform well. So we looked into how the templating engine works, and it turns out that the templates are compiled into Python functions. This means that a big template can turn into a really enormous Python function (Python version of the example). For some reason really enormous Python functions aren't handled particularly well by the JIT, and in the next section I'll explain some the background that's necessary to understand why this happens.
Trace Limits and Inlining
To understand why the problem occurs, it's necessary to understand how PyPy's trace limit and inlining works. The tracing JIT has a maximum trace length built in, the reason for that is some limitation in the compact encoding of traces in the JIT. Another reason is that we don't want to generate arbitrary large chunks of machine code. Usually, when we hit the trace limit, it is due to inlining. While tracing, the JIT will inline many of the functions called from the outermost one. This is usually good and improves performance greatly, however, inlining can also lead to the trace being too long. If that happens, we will mark a called function as uninlinable. The next time we trace the outer function we won't inline it, leading to a shorter trace, which hopefully fits the trace limit.

In the diagram above we trace a function f, which calls a function g, which
is inlined into the trace. The trace ends up being too long, so the JIT
disables inlining of g. The next time we try to trace f the trace will
contain a call to g instead of inlining it. The trace ends up being not too
long, so we can turn it into machine code when tracing finishes.
Now we know enough to understand what the problem with automatically generated code is: sometimes, the outermost function itself doesn't fit the trace limit, without any inlining going on at all. This is usually not the case for normal, hand-written Python functions. However, it can happen for automatically generated Python code, such as the code that the Tornado templating engine produces.
So, what happens when the JIT hits such a huge function? The function is traced until the trace is too long. Then the trace limits stops further tracing. Since nothing was inlined, we cannot make the trace shorter the next time by disabling inlining. Therefore, this happens again and again, the next time we trace the function we run into exactly the same problem. The net effect is that the function is even slowed down: we spend time tracing it, then stop tracing and throw the trace away. Therefore, that effort is never useful, so the resulting execution can be slower than not using the JIT at all!
Solution
To get out of the endless cycle of useless retracing we first had the idea of simply disabling all code generation for such huge functions, that produce too long traces even if there is no inlining at all. However, that lead to disappointing performance in the example Tornado program, because important parts of the code remain always interpreted.
Instead, our solution is now as follows: After we have hit the trace limit and no inlining has happened so far, we mark the outermost function as a source of huge traces. The next time we trace such a function, we do so in a special mode. In that mode, hitting the trace limit behaves differently: Instead of stopping the tracer and throwing away the trace produced so far, we will use the unfinished trace to produce machine code. This trace corresponds to the first part of the function, but stops at a basically arbitrary point in the middle of the function.
The question is what should happen when execution reaches the end of this unfinished trace. We want to be able to cover more of the function with machine code and therefore need to extend the trace from that point on. But we don't want to do that too eagerly to prevent lots and lots of machine code being generated. To achieve this behaviour we add a guard to the end of the unfinished trace, which will always fail. This has the right behaviour: a failing guard will transfer control to the interpreter, but if it fails often enough, we can patch it to jump to more machine code, that starts from this position. In that way, we can slowly explore the full gigantic function and add all those parts of the control flow graph that are actually commonly executed at runtime.

In the diagram we are trying to trace a huge function f, which leads to
hitting the trace limit. However, nothing was inlined into the trace, so
disabling inlining won't ensure a successful trace attempt the next time.
Instead, we mark f as "huge". This has the effect that when we trace it again
and are about to hit the trace limit, we end the trace at an arbitrary point by
inserting a guard that always fails.

If this guard failure is executed often enough, we might patch the guard and
add a jump to a further part of the function f. This can continue potentially
several times, until the trace really hits and end points (for example by
closing the loop and jumping back to trace 1, or by returning from f).
Evaluation
Since this is a performance cliff that we didn't observe in any of our benchmarks ourselves, it's pointless to look at the effect that this improvement has on existing benchmarks – there shouldn't and indeed there isn't any.
Instead, we are going to look at a micro-benchmark that came out of the original bug report, one that simply renders a big artificial Tornado template 200 times. The code of the micro-benchmark can be found here.
All benchmarks were run 10 times in new processes. The means and standard deviations of the benchmark runs are:
| Implementation | Time taken (lower is better) |
|---|---|
| CPython 3.9.5 | 14.19 ± 0.35s |
| PyPy3 without JIT | 59.48 ± 5.41s |
| PyPy3 JIT old | 14.47 ± 0.35s |
| PyPy3 JIT new | 4.89 ± 0.10s |
What we can see is that while the old JIT is very helpful for this micro-benchmark, it only brings the performance up to CPython levels, not providing any extra benefit. The new JIT gives an almost 3x speedup.
Another interesting number we can look at is how often the JIT started a trace, and for how many traces we produced actual machine code:
| Implementation | Traces Started | Traces sent to backend | Time spent in JIT |
|---|---|---|---|
| PyPy3 JIT old | 216 | 24 | 0.65s |
| PyPy3 JIT new | 30 | 25 | 0.06s |
Here we can clearly see the problem: The old JIT would try tracing the auto-generated templating code again and again, but would never actually produce any machine code, wasting lots of time in the process. The new JIT still traces a few times uselessly, but then eventually converges and stops emitting machine code for all the paths through the auto-generated Python code.
Related Work
Tim Felgentreff pointed me to the fact that Truffle also has a mechanism to slice huge methods into smaller compilation units (and I am sure other JITs have such mechanisms as well).
Conclusion
In this post we've described a performance cliff in PyPy's JIT, that of really big auto-generated functions which hit the trace limit without inlining, that we still want to generate machine code for. We achieve this by chunking up the trace into several smaller traces, which we compile piece by piece. This is not a super common thing to be happening – otherwise we would have run into and fixed it earlier – but it's still good to have a fix now.
The work described in this post tiny bit experimental still, but we will release it as part of the upcoming 3.8 beta release, to get some more experience with it. Please grab a 3.8 release candidate, try it out and let us know your observations, good and bad!
#pypy IRC moves to Libera.Chat
Following the example of many other FOSS projects, the PyPy team has
decided to move its official #pypy IRC channel from Freenode to
Libera.Chat: irc.libera.chat/pypy
The core devs will no longer be present on the Freenode channel, so we recommend to join the new channel as soon as possible.
wikimedia.org has a nice guide on how to setup your client to migrate from Freenode to Libera.Chat.
PyPy v7.3.5: bugfix release of python 2.7 and 3.7
PyPy v7.3.5: release of 2.7 and 3.7
We are releasing a PyPy 7.3.5 with bugfixes for PyPy 7.3.4, released April 4. PyPy 7.3.4 was the first release that runs on windows 64-bit, so that support is still "beta". We are releasing it in the hopes that we can garner momentum for its continued support, but are already aware of some problems, for instance it errors in the NumPy test suite (issue 3462). Please help out with testing the releae and reporting successes and failures, financially supporting our ongoing work, and helping us find the source of these problems.
The new windows 64-bit builds improperly named c-extension modules with the same extension as the 32-bit build (issue 3443)
Use the windows-specific
PC/pyconfig.hrather than the posix oneFix the return type for
_Py_HashDoublewhich impacts 64-bit windowsA change to the python 3.7
sysconfig.get_config_var('LIBDIR')was wrong, leading to problems finding libpypy3-c.so for embedded PyPy (issue 3442).Instantiate
distutils.command.installschema for PyPy-specificimplementation_lowerDelay thread-checking logic in greenlets until the thread is actually started (continuation of issue 3441)
-
Four upstream (CPython) security patches were applied:
Fix for json-specialized dicts (issue 3460)
Specialize
ByteBuffer.setslicewhich speeds up binary file reading by a factor of 3When assigning the full slice of a list, evaluate the rhs before clearing the list (issue 3440)
On Python2,
PyUnicode_Containsaccepts bytes as well as unicode.Finish fixing
_sqlite3- untested_reset()was missing an argument (issue 3432)Update the packaged sqlite3 to 3.35.5 on windows. While not a bugfix, this seems like an easy win.
We recommend updating. These fixes are the direct result of end-user bug reports, so please continue reporting issues as they crop up.
You can find links to download the v7.3.5 releases here:
We would like to thank our donors for the continued support of the PyPy project. If PyPy is not quite good enough for your needs, we are available for direct consulting work. If PyPy is helping you out, we would love to hear about it and encourage submissions to our renovated blog site via a pull request to https://github.com/pypy/pypy.org
We would also like to thank our contributors and encourage new people to join the project. PyPy has many layers and we need help with all of them: PyPy and RPython documentation improvements, tweaking popular modules to run on PyPy, or general help with making RPython's JIT even better.
If you are a python library maintainer and use C-extensions, please consider making a CFFI / cppyy version of your library that would be performant on PyPy. In any case both cibuildwheel and the multibuild system support building wheels for PyPy.
What is PyPy?
PyPy is a Python interpreter, a drop-in replacement for CPython 2.7, 3.7, and soon 3.8. It's fast (PyPy and CPython 3.7.4 performance comparison) due to its integrated tracing JIT compiler.
We also welcome developers of other dynamic languages to see what RPython can do for them.
This PyPy release supports:
x86 machines on most common operating systems (Linux 32/64 bits, Mac OS X 64 bits, Windows 32/64 bits, OpenBSD, FreeBSD)
big- and little-endian variants of PPC64 running Linux,
s390x running Linux
64-bit ARM machines running Linux.
PyPy does support ARM 32 bit processors, but does not release binaries.
Some Ways that PyPy uses Graphviz
Some way that PyPy uses Graphviz
Somebody wrote this super cool thread on Twitter about using Graphviz to make software visualize its internal state:
PyPy is using this approach a lot too and I collected a few screenshots of that technique on Twitter and I thought it would make a nice blog post too!
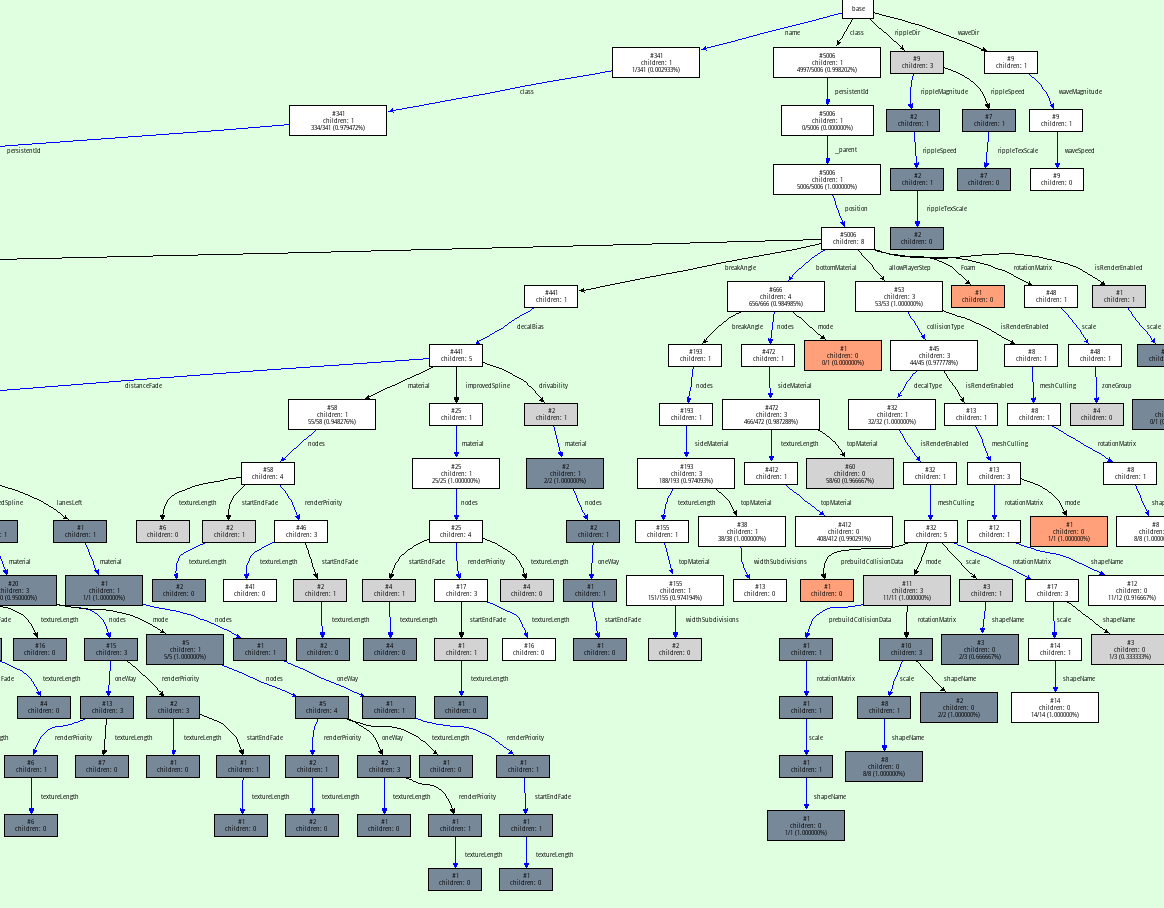
The most important view early in the project, and the way that our Graphviz visualizations got started was that we implemented a way to look at the control flow graphs of our RPython functions after type inference. They are in static single information form (SSI), a variant of SSA form. Hovering over the variables shows the inferred types in the footer:
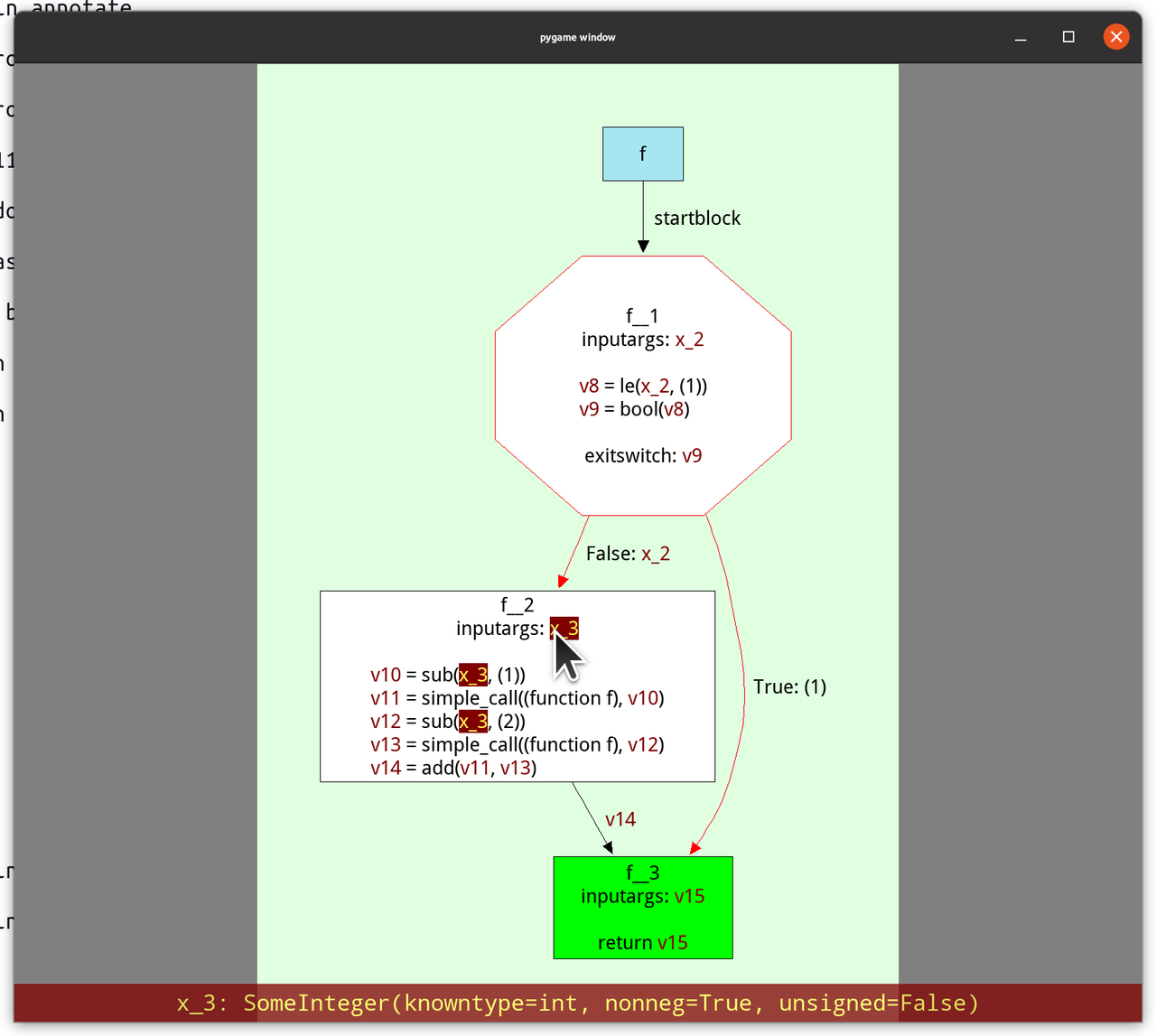
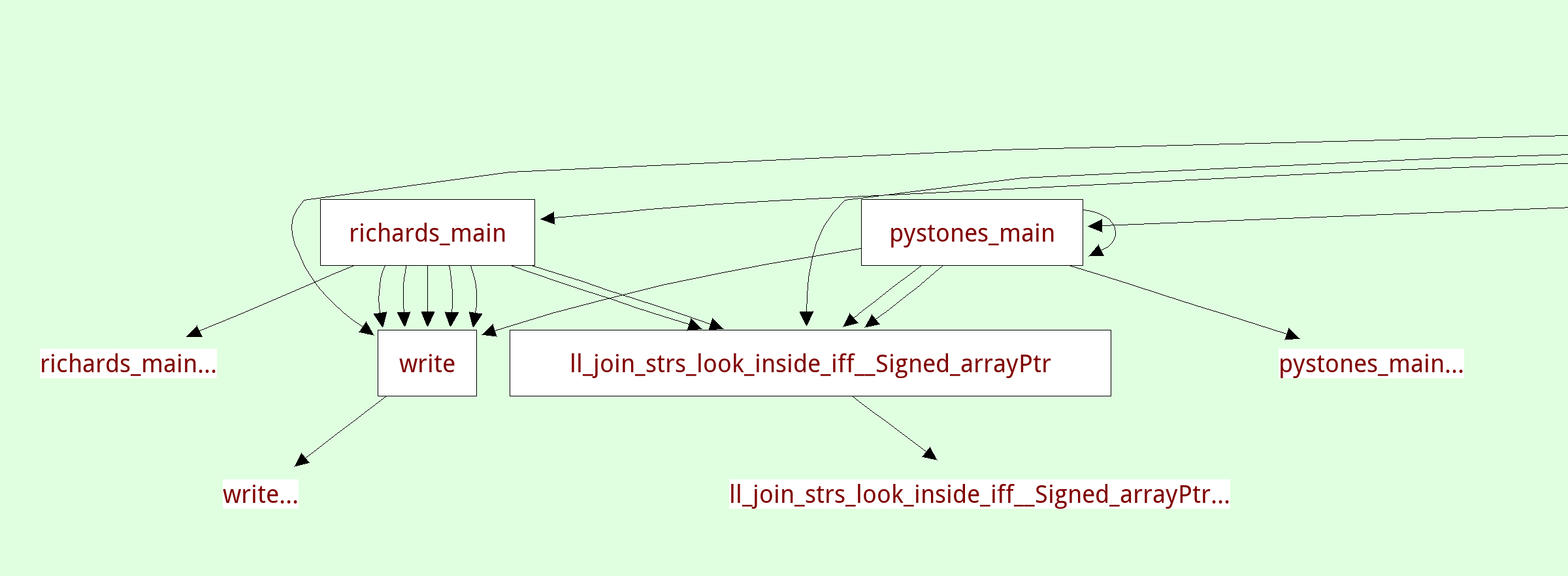
There's another view that shows the inferred call graph of the program:
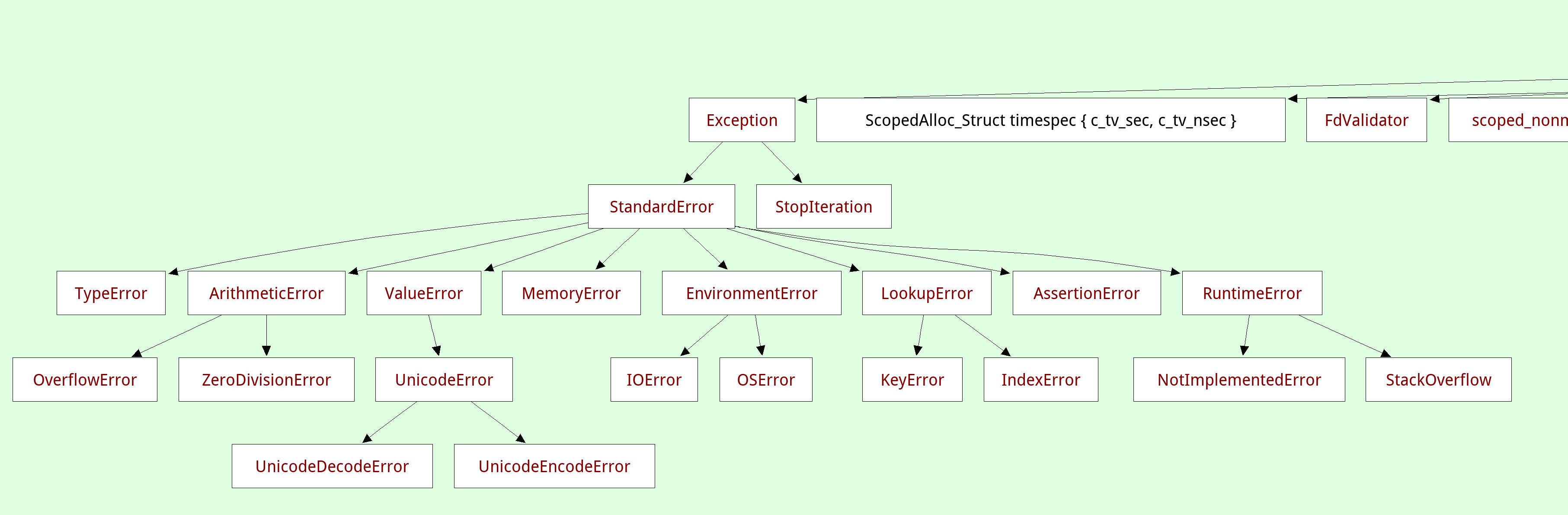
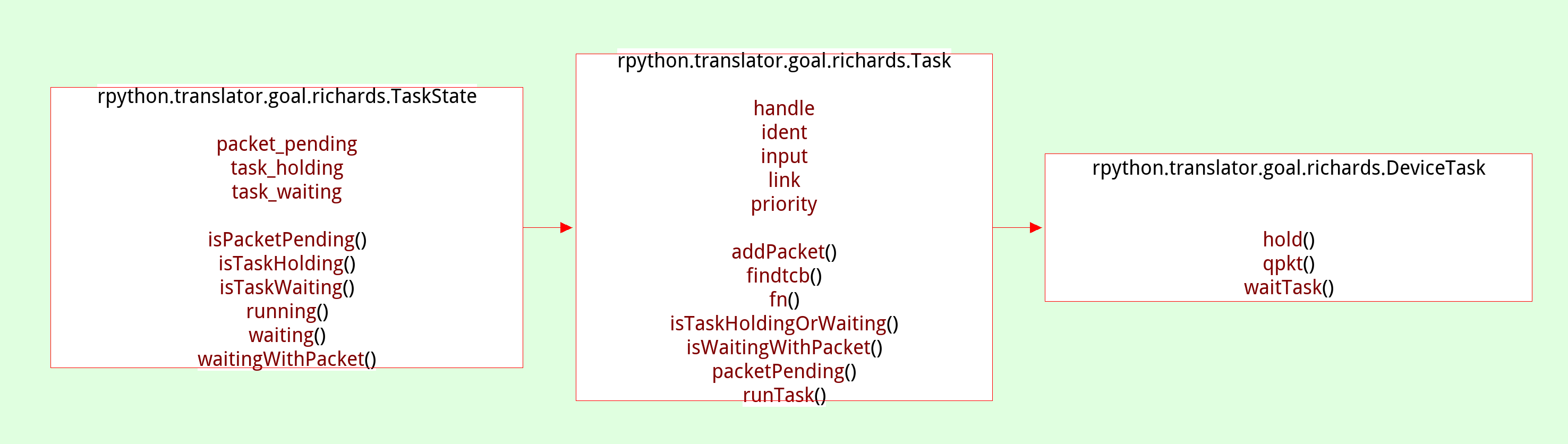
A related viewer shows the inferred class hierarchy (in this case the exception hierarchy) and you can focus on a single class, which will show you its base classes and all the methods and instance attributes that were found:
We also have a view to show us the traces that are produced by the tracing JIT tests. this viewer doesn't really scale to the big traces that the full Python interpreter produces, but it's really useful during testing:

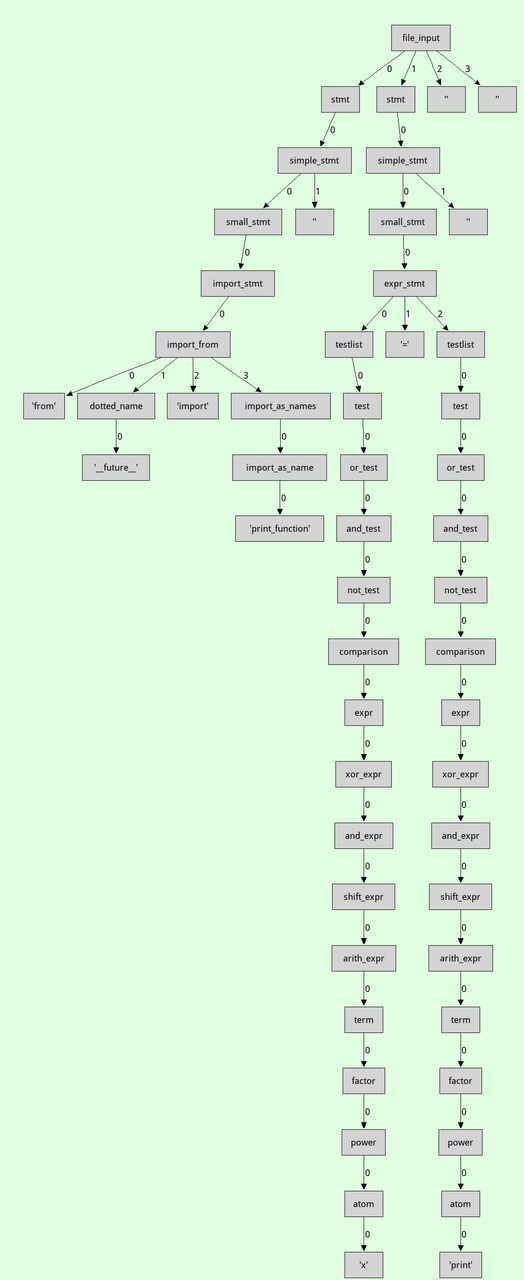
Then there are more traditional tree views, eg here is a parse tree for a small piece of Python source code:
Parsing-related we have visualized the DFAs of the parser in the past, though the code is unfortunately lost.
All these visualizations are made by walking the relevant data structures and producing a Graphviz input file using a bit of string manipulation, which is quite easy to do. Knowing a bit of Graphviz is a really useful skill, it's super easy to make throwaway visualizations.
For example here is a one-off thing I did when debugging our JSON parser to show the properties of the objects used in a huge example json file:
On top of graphviz, we have a custom tool called the dotviewer, which is written in Python and uses Pygame to give you a zoomable, pannable, searchable way to look at huge Graphviz graphs. All the images in this post are screenshots of that tool. In its simplest form it takes any .dot files as input.
Here's a small video dotviewer, moving around and searching in the json graph. By writing a bit of extra Python code the dotviewer can also be extended to add hyperlinks in the graphs to navigate to different views (for example, we did that for the callgraphs above).
All in all this is a really powerful approach to understand the behaviour of some of code, or when debugging complicated problems and we have gotten a huge amount of milage out of this over the years. It can be seen as an instance of moldable development ("a way of programming through which you construct custom tools for each problem"). And it's really easy to get into! The Graphviz language is quite a simple text-based language that can be applied to a huge amount of different visualization situations.
PyPy v7.3.4: release of python 2.7 and 3.7
PyPy v7.3.4: release of python 2.7 and 3.7
The PyPy team is proud to release the version 7.3.4 of PyPy, which includes two different interpreters:
PyPy2.7, which is an interpreter supporting the syntax and the features of Python 2.7 including the stdlib for CPython 2.7.18+ (the
+is for backported security updates)PyPy3.7, which is an interpreter supporting the syntax and the features of Python 3.7, including the stdlib for CPython 3.7.10. We no longer refer to this as beta-quality as the last incompatibilities with CPython (in the
remodule) have been fixed.
We are no longer releasing a Python3.6 version, as we focus on updating to Python 3.8. We have begun streaming the advances towards this goal on Saturday evenings European time on https://www.twitch.tv/pypyproject. If Python3.6 is important to you, please reach out as we could offer sponsored longer term support.
The two interpreters are based on much the same codebase, thus the multiple release. This is a micro release, all APIs are compatible with the other 7.3 releases. Highlights of the release include binary Windows 64 support, faster numerical instance fields, and a preliminary HPy backend.
A new contributor (Ondrej Baranovič - thanks!) took us up on the challenge to get windows 64-bit support. The work has been merged and for the first time we are releasing a 64-bit Windows binary package.
The release contains the biggest change to PyPy's implementation of the
instances of user-defined classes in many years. The optimization was
motivated by the report of performance problems running a numerical particle
emulation. We implemented an optimization that stores int and float
instance fields in an unboxed way, as long as these fields are type-stable
(meaning that the same field always stores the same type, using the principle
of type freezing). This gives significant performance improvements on
numerical pure-Python code, and other code where instances store many integers
or floating point numbers.
There were also a number of optimizations for methods around strings and bytes, following user reported performance problems. If you are unhappy with PyPy's performance on some code of yours, please report an issue!
A major new feature is prelminary support for the Universal mode of HPy: a
new way of writing c-extension modules to totally encapsulate PyObject*.
The goal, as laid out in the HPy documentation and recent HPy blog post,
is to enable a migration path
for c-extension authors who wish their code to be performant on alternative
interpreters like GraalPython (written on top of the Java virtual machine),
RustPython, and PyPy. Thanks to Oracle and IBM for sponsoring work on HPy.
Support for the vmprof statistical profiler has been extended to ARM64 via a built-in backend.
Several issues exposed in the 7.3.3 release were fixed. Many of them came from the great work ongoing to ship PyPy-compatible binary packages in conda-forge. A big shout out to them for taking this on.
Development of PyPy takes place on https://foss.heptapod.net/pypy/pypy. We have seen an increase in the number of drive-by contributors who are able to use gitlab + mercurial to create merge requests.
The CFFI backend has been updated to version 1.14.5 and the cppyy backend to 1.14.2. We recommend using CFFI rather than C-extensions to interact with C, and using cppyy for performant wrapping of C++ code for Python.
As always, we strongly recommend updating to the latest versions. Many fixes are the direct result of end-user bug reports, so please continue reporting issues as they crop up.
You can find links to download the v7.3.4 releases here:
We would like to thank our donors for the continued support of the PyPy project. If PyPy is not quite good enough for your needs, we are available for direct consulting work. If PyPy is helping you out, we would love to hear about it and encourage submissions to our renovated blog site via a pull request to https://github.com/pypy/pypy.org
We would also like to thank our contributors and encourage new people to join the project. PyPy has many layers and we need help with all of them: PyPy and RPython documentation improvements, tweaking popular modules to run on PyPy, or general help with making RPython's JIT even better. Since the previous release, we have accepted contributions from 10 new contributors, thanks for pitching in, and welcome to the project!
If you are a python library maintainer and use C-extensions, please consider making a cffi / cppyy version of your library that would be performant on PyPy. In any case both cibuildwheel and the multibuild system support building wheels for PyPy.
What is PyPy?
PyPy is a Python interpreter, a drop-in replacement for CPython 2.7, 3.7, and soon 3.8. It's fast (PyPy and CPython 3.7.4 performance comparison) due to its integrated tracing JIT compiler.
We also welcome developers of other dynamic languages to see what RPython can do for them.
This PyPy release supports:
x86 machines on most common operating systems (Linux 32/64 bits, Mac OS X 64 bits, Windows 32/64 bits, OpenBSD, FreeBSD)
big- and little-endian variants of PPC64 running Linux,
s390x running Linux
64-bit ARM machines running Linux.
PyPy does support ARM 32 bit processors, but does not release binaries.
What else is new?
For more information about the 7.3.4 release, see the full changelog.
Please update, and continue to help us make PyPy better.
Cheers, The PyPy team
New HPy blog
Regular readers of this blog already know about HPy, a project which aims to develop a new C API for Python to make it easier/faster to support C extensions on alternative Python implementations, including PyPy.
The HPy team just published the first post of HPy new blog, so if you are interested in its development, make sure to check it out!
PyPy's blog has moved
For many years, PyPy has been publishing blog posts at https://morepypy.blogspot.com. From now on, the posts will be here, at https://pypy.org/blog. The RSS feed is https://pypy.org/rss.xml. The original content has been migrated to the newer site, including comments.
Mac meets Arm64
Apple now ships Macs which are running on an arm64 variant machine with the latest version of MacOS, Big Sur M1. We are getting requests for PyPy to support this new architecture. Here is our position on this topic (or at least mine, Armin Rigo's), and how you can help.
Porting PyPy is harder than just re-running the compiler, because PyPy contains a few big architecture-dependent "details", like the JIT compiler and the foreign function interfaces (CFFI and ctypes).
Fixing the JIT compiler should not be too much work: we already support arm64, just the Linux one. But Apple made various details different (like the calling conventions). A few other parts need to be fixed too, notably CFFI and ctypes, again because of the calling conventions.
Fixing that would be a reasonable amount of work. I would do it myself for a small amount of money. However, the story doesn't finish here. Obviously, the start of the story would be to get ssh access to a Big Sur M1 machine. (If at this point you're thinking "sure, I can give you ssh access for three months", then please read on.) The next part of the story is that we need a machine available long term. It can be either a machine provided and maintained by a third party, or alternatively a pot of money big enough to support the acquision of a machine and ongoing work of one of us.
If we go with the provided-machine solution: What we need isn't a lot of resources. Our CI requires maybe 10 GB of disk space, and a few hours of CPU per run. It should fit into 8 GB of RAM. We normally do a run every night but we can certainly lower the frequency a bit if that would help. However, we'd ideally like some kind of assurance that you are invested into maintaining the machine for the next 3-5 years (I guess, see below). We had far too many machines that disappeared after a few months.
If we go with the money-supported solution: it's likely that after 3-5 years the whole Mac base will have switched to arm64, we'll drop x86-64 support for Mac, and we'll be back to the situation of the past where there was only one kind of Mac machine to care about. In the meantime, we are looking at 3-5 years of lightweight extra maintenance. We have someone that has said he would do it, but not for free.
If either of these two solutions occurs, we'll still have, I quote, "probably some changes in distutils-type stuff to make python happy", and then some packaging/deployment changes to support the "universal2" architecture, i.e. including both versions inside a single executable (which will not be just an extra switch to clang, because the two versions need a different JIT backend and so must be translated separately).
So, now all the factors are on the table. We won't do the minimal "just the JIT compiler fixes" if we don't have a plan that goes farther. Either we get sufficient money, and maybe support, and then we can do it quickly; or PyPy will just remain not natively available on M1 hardware for the next 3-5 years. We are looking forward to supporting M1, and view resources contributed by the community as a vote of confidence in assuring the future of PyPy on this hardware. Contact us: pypy-dev@python.org, or our private mailing list pypy-z@python.org.
Thanks for reading!
Armin Rigo
if you post a crowdsourcing link (e.g. gofundme, etc) I'd be happy to contribute, and now that it's hit the front page of HN, I'm sure lots of other people would join. M1 macs are pretty inexpensive.
p.s. thanks!!! for all the work - I use pypy regularly.
I have an M1 MacBook Air that I could give you SSH access to but it will come to me in mid January.
ditto on the crowdsource
You can contribute to PyPy on their Open Collective page:
https://opencollective.com/pypy
done.
M1 Macs for CI are available for free for open source developers. See: https://www.macstadium.com/opensource
@Anonymous: like many others, MacStadium is conflating "open source" with "hobbyist" by adding this clause: "Open source project may not (...)receive funding from commercial companies or organizations (NGO, education, research or governmental). (...) Contributors who are paid to work on the project are not eligible." The point of my blog post was precisely that I won't do it for free.
It seems like it might be worth reaching out to MacStadium about it regardless. They've got Golang, Rust, Node, NumFocus, and Monero listed on their support page https://www.macstadium.com/opensource-members which suggests to me that this language might just be a hamfistedly awkward attempt to avoid somebody at Facebook trying to get a free fleet of mac minis out of open sourcing their SDK or something.